OSDF Data Origin Hardware Examples
We are actively collecting hardware examples for OSDF, if you would like to submit one email us at [email protected] to be featured.
OSG has no official recommendation for hardware or storage system architectures, all examples below are from community submissions.
US CMS Tier-2 Center - University of California, San Diego
Ceph storage system for the US CMS Tier-2 Center in the experimental particle physics group at the University of California, San Diego.
Overview
Budget
$400,000
Pros
- Cheap large volume storage (7.2PB usable) at a good performance (288Gbit/sec theoretical max IO, 100Gbit/sec to WAN)
- Not too effort-intensive to operate.
Cons
- All redundancy is disk level instead of node level.
- When Ceph crashes it can be painful to rebuild in its entirety. This and possible solutions are discussed below.
Implementation
$400k allows the purchase of 6 storage systems, two headnodes each, a 25Gbps switch with 6x100Gbps uplinks, and a Kubernetes (K8S) node with a single 100Gbps NIC. With 3 disk redundancy erasure encoding this provides a total of roughly 1.2PB of Real Byte Capacity of usable storage per array, or 7.2PB usable storage total.
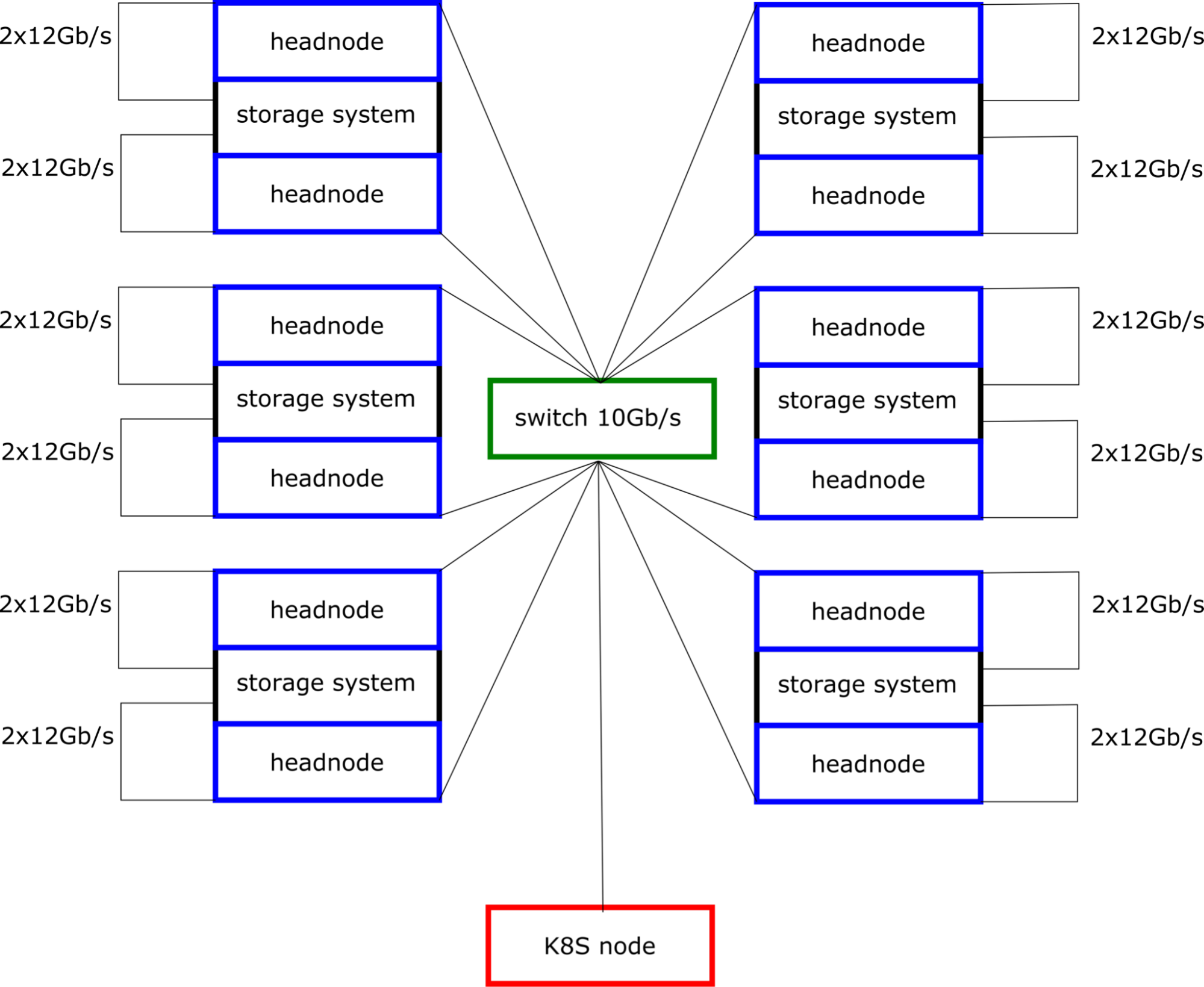
The individual storage chassis include 102 20TB enterprise quality HDDs. These are extra long chassis that require special racks to accommodate them.
We have recent quotes for one of these from multiple vendors at $50k. We connect them up to the network via 2 headnodes. Each headnode is connected to the disk array via 2x12Gbps special connectors. Each storage node thus theoretically can bring 4x12=48Gbps to the headnodes combined, and we connect each head node at 25Gbps to the top of the rack switch. Each disk array thus has 48Gbps theoretical capacity to the K8S node on the top-of-rack (TOR) switch.
For the purpose of an OSDF data origin, it is plenty sufficient to have 100Gbps theoretical bandwidth via the K8S host. 6 disk arrays would provide 6x48=288Gbit/sec, plenty enough headroom for the storage arrays to be able to serve a local cluster, and WAN traffic never negatively affecting the local data access.
We estimate the other components to cost $6k per head node, $30k for a TOR switch each for data and control, $10k for the K8S node with 100Gbps NIC, and a few thousand for the rack and power installation, etc. The data switch was mentioned previously as providing 25Gbps ports, or just multiple 10Gbps, whatever is more convenient. The control switch can be something really simple, say a 1Gbit/sec switch that is inexpensive. These are all rough numbers that should fit into the budget given that the bulk of the cost is in the storage infrastructure. Whether or not a 7th disk array fits into the price depends on detailed pricing. Also, whether or not 18TB or 20TB are more cost-effective for disks depends on the details of actual quotes. We used a 20TB HDD for the size calculations.
We chose to implement Ceph such that we get triple disk redundancy but not system redundancy. We chose to do that in order to maximize storage by minimizing costs for chassis & headnodes. I.e. we based our infrastructure on the largest disk arrays we could find for sale. If you wanted Ceph to be deployed with system redundancy then you need more and smaller systems, and thus invariably will be spending more money on enclosures, CPUs, RAM, headnodes, etc.
For 102 disks deployed with triple-redundant erasure encoding into two arrays, one for each headnode, we arrive at roughly 1.2PB usable disk space per disk array, or 7.2PB total for the 6 arrays together.
- The storage headnodes only run services required to operate CephFS.
- We deliberately chose to isolate the OSDF Data Origin on a separate piece of hardware to be conservative, and to meet the architecture described in the OSG documentation, i.e. the K8S node straddles a potential firewall.
Storage Use
We support primarily data analysis of CMS data from the LHC.
Roughly 50 active users with significant storage accounts.
Roughly 1,000 users that use the cluster and read data from storage that they process. None of these users have accounts on our systems. They use OSG middleware to use the cluster via CMS’s HTCondor pool of the Open Science Compute Federation ( OSCF ).
The data that is read by the bulk of the users has typical file sizes between 100MB to ~2GB.
We impose a minimum filesize of 10MB onto the users. The actual policy was chosen in some negotiation with the users to allow all things reasonable that they need to do, but also to disallow unreasonably small files that could hurt performance for all. We do not have real evidence for this being an issue but wanted to play it safe as we started our Ceph adventure. In addition, having millions of small files wastes storage if the files are smaller than the default minimal size in Ceph. We have limited system management effort (one person to operate all storage, all services, a set of login nodes, and a 10,000 core cluster, and a large number of eclectic hardware for R&D purposes), and felt that we needed to put a policy in place to minimize operational headaches.
Currently in Operation at UCSD
We presently operate a system that includes 5 such disk arrays instead of the 6 proposed above. The only difference to the proposed above is that we are short on 10Gbps ports in our infrastructure, and don’t have a 100Gbps K8S host. Instead, we connect each head node at 10Gbps, and have 6x10Gbps origin servers from a hardware purchase many years ago.
Our TOR switching infrastructure supports 2x100 Gbit to the network edge of UC San Diego. This is more than the 5x20 provisioned to support Ceph because we have other needs for bandwidth out of our computer room in the physics department.
We have seen sustained peak IO at 80-90% of the theoretical as long as there are lots of clients hitting the system, all reading/writing reasonably sequentially reasonably large files from the file system. See our filesize policy above.
What we have learned
We are very new to using Ceph with only a few months of experience.
- So far had one painful crash of Ceph requiring a few days of maintenance to fix it.
- We are following other more experienced people in our Ceph deployment.
- Most notably Caltech and the Flatiron Institute. See this seminar by Pataki on YouTube.
In hindsight maybe we would have been better off having each headnode its own erasure encoded independent filesystem and not aggregate all of them into one CephFS namespace. We could have made a single namespace at the OSDF out of our origins, and thus have a much smaller entity to rebuild upon failure.
Such an arrangement would still have its own drawbacks, as it bifurcates the total volume with all the issues of having individual size limits of each individual CephFS filesystem. Maybe something worth trying out if the current deployment needs to be rebuilt too often.