Friday Exercise 2.2: Workflow Optimization and Scaling¶
If you finish the entire workflow and are thirsty for more, try any of the following in whatever order you like:
Bonus 1¶
Rerun the DAG again with four times the permutations per job (but fewer processes, keeping a total of 100,000 permutations per trait). Which DAG finished in an overall faster time? Why?
Bonus 2¶
You probably noticed that the job processes from the permutation step create many log, out, and error files. Modify the permutation submit files to better organize these files into subdirectories (check out HTCondor's IntitialDir feature and/or DAG's DIR features). You may wish to always test the DAG using fewer permutations and permutations processes for a quick turnaround.
Bonus 3¶
Take the workflow to the submit server for the Open Science Grid (osg-learn.chtc.wisc.edu), and run it there.
What happens?
- Do all of the jobs complete successfully? (Check for the desired output files and examine the
runR_*.outfiles, which are created by therunR.plwrapper and indicate any errors from the R script, even if HTCondor thought the job was successful.) - If there are any errors (likely related to machine differences and/or software dependencies), implement a RETRY for jobs that fail, accounting for the fact that a DAG
RETRYstatement applies to an entire submit file (JOB), while you might actually need to account for process-specific errors.
Bonus 4¶
This isn't actual a bonus, but links to a sample workflow diagram and DAG schematic:
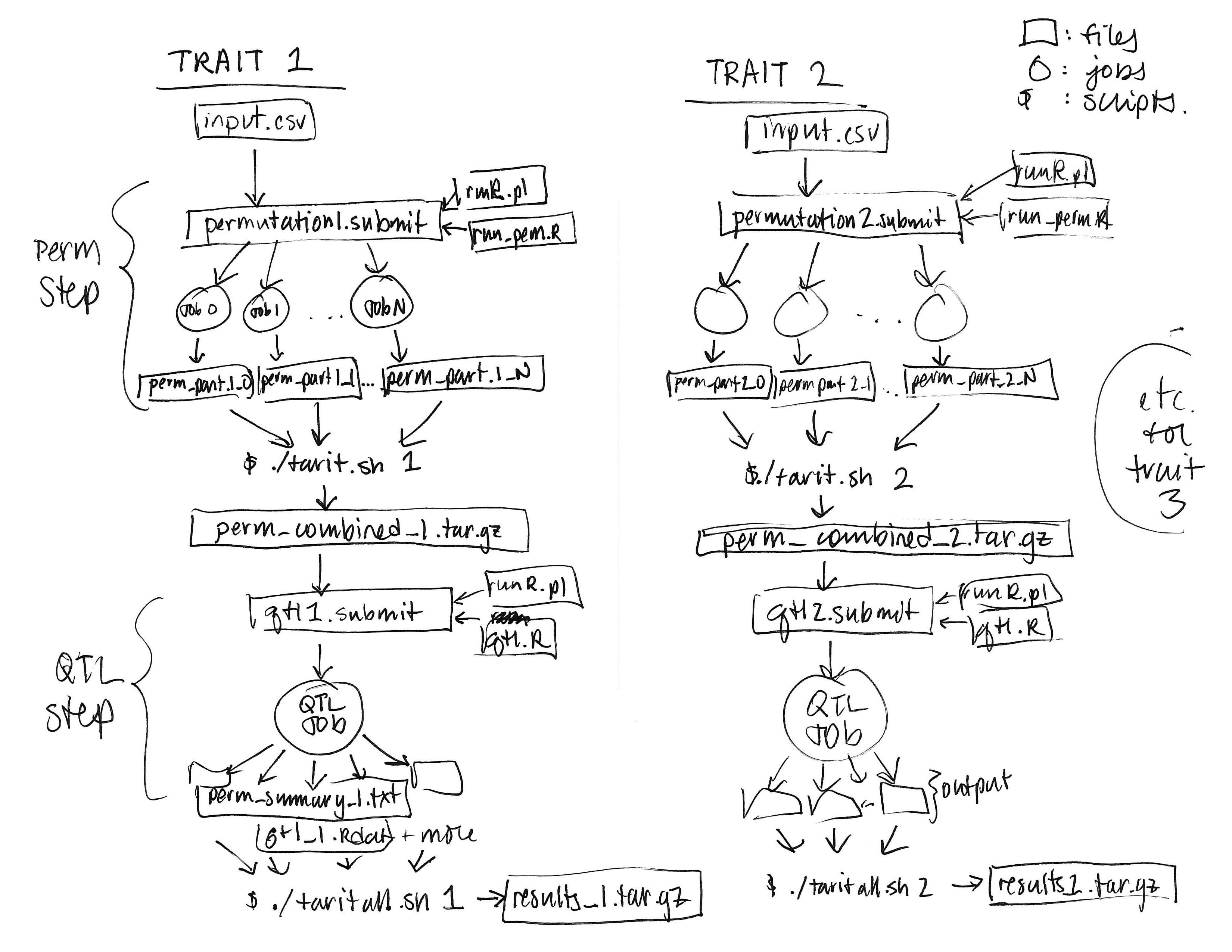{kind=link}
{kind=link}
And also how to download and look at a solution workflow:
username@learn $ wget http://proxy.chtc.wisc.edu/SQUID/osgschool19/WorkflowComplete.tar.gz username@learn $ tar -xzf WorkflowComplete.tar.gz